Preprints (© corresponding authors, ♯ co-first authors)
How to Train Your Deep Research Agent? Prompt, Reward, and Policy Optimization in Search-R1
Abstract: Arxiv technical report, 2026 Paper / Link
Do MLLMs Really Understand Space? A Mathematical Reasoning Evaluation
Abstract: Arxiv technical report, 2026 Paper / Link / Website
Reassessing the Role of Supervised Fine-Tuning: An Empirical Study in VLM Reasoning
Abstract: Arxiv technical report, 2025 Paper / Link
To Trust Or Not To Trust Your Vision-Language Model's Prediction
Abstract: Arxiv technical report, 2025 Paper / Link / Code
Stay Unique, Stay Efficient: Preserving Model Personality in Multi-Task Merging
Abstract: Arxiv technical report, 2025 Paper / Link / Code
Test-Time Immunization: A Universal Defense Framework Against Jailbreaks for (Multimodal) Large Language Models
Abstract: Arxiv technical report, 2025 Paper / Link
Towards Compatible Fine-tuning for Vision-Language Model Updates
Abstract: Arxiv technical report, 2024 Paper / Link
Which Model to Transfer? A Survey on Transferability Estimation
Abstract: Arxiv technical report, 2024 Paper / Link
Self-training solutions for the ICCV 2023 GeoNet Challenge
Abstract: Technical report (🏆Winners in the [universal DA track] of GeoNet workshop challenges), 2023 Paper / Code / Leaderboard
Benchmarking Test-Time Adaptation against Distribution Shifts in Image Classification
Abstract: Arxiv technical report, 2023 Paper / Link / Code
AUTO: Adaptive Outlier Optimization for Online Test-Time OOD Detection
Abstract: Arxiv technical report, 2023 Paper / Link
UMAD: Universal Model Adaptation under Domain and Category Shift
Abstract: Arxiv technical report, 2021 Paper / Link
Semi-Supervised Domain Generalizable Person Re-Identification
Abstract: Arxiv technical report, 2021 Paper / Link
On Evolving Attention Towards Domain Adaptation
Abstract: Arxiv technical report, 2021 Paper / Link
Robust Localized Multi-view Subspace Clustering
Abstract: Arxiv technical report, 2017 Paper / Link Journal Submission/ Revision
A Comprehensive Survey on Trustworthiness in Reasoning with Large Language Models
Abstract: Submitted, 2025 Paper / Taxonomy / Code
Improving Generalizable Person Re-identification by Mimicking Embedding via Adaptive Aggregation
Abstract: Submitted, 2025
Harmonizing and Merging Source Models for CLIP-based Domain Generalization
Abstract: Submitted, 2025 Paper / Link
Personalized Federated Learning via Dual-Prompt Optimization and Cross Fusion
Abstract: Submitted, 2025 Paper / Link
Adapting Vision-Language Models Without Labels: A Comprehensive Survey
Abstract: International Journal of Computer Vision (IJCV), Major revision, 2025 Paper / Link / Code
Prototypical Distillation and Debiased Tuning for Black-box Unsupervised Domain Adaptation
Abstract: International Journal of Computer Vision (IJCV), Major revision, 2025 Paper / Link Workshops & Extended Abstracts
Understanding gradient inversion attacks from the prior knowledge perspective
Abstract: In this blogpost, we mention multiple works in gradient inversion attacks, point out the chanllenges we need to solve in GIAs, and provide a perspective from the prior knowledge to understand the logic behind recent papers. International Conference on Learning Representations (ICLR), BlogPosts, 2024 Link
Pseudo-Calibration: Improving Predictive Uncertainty Estimation in Domain Adaptation
Abstract: NeurIPS DistShift Workshop, 2023 Paper / Link / Code
Simplifying and Stabilizing Model Selection in Unsupervised Domain Adaptation
Abstract: NeurIPS DistShift Workshop, 2023 Paper / Link / Code
A Functional Connectome-based Interspecies Model Boosts Classification in Neuropsychiatric Disorders
Abstract: ISMRM, 2019 Link Publications [2026] [2025] [2024] [2023] [2022] [2021] [2020] [2019] [2018] [2017] [2016] [2015]
Multi-View Images Suffice 3D Reasoning Through Chain-of-Thought Selection and Question-Guided Fusion
Abstract: IEEE Transactions on Image Processing (TIP), 2026 Paper / Link
Procedure-Aware Hierarchical Alignment for Open Surgery Video-Language Pretraining
Abstract: IEEE Transactions on Image Processing (TIP), 2026 Paper / Link
Ranking Vision-Language Models in Fully Unlabeled Tasks
Abstract: IEEE Transactions on Multimedia (TMM), 2026 Paper / Link
Harmonizing Class Uniformity and Separability for Transferability Estimation
Abstract: Pattern Recognition (PR), 2026 Paper / Link
Spectral Decomposition and Adaptation for Non-stationary Time Series Anomaly Detection
Abstract: Neurocomputing, 2026 Paper / Link
USE: A Unified Self-Ensembling Framework for Test-Time Prompt Tuning
Abstract: International Conference on Machine Learning (ICML), 2026 Paper / Link
Mitigating the Safety–Utility Trade-off in LLM Alignment via Adaptive Safe Context Learning
Abstract: International Conference on Machine Learning (ICML), 2026 Paper / Link
Reranker Helps, but Not Enough: Towards Strong Poisoning Attacks Against Retrieval-Augmented Generation
Abstract: International Conference on Machine Learning (ICML), 2026 Paper / Link
Modeling Long-Tail Relations in the Operating Room via In-Context Multimodal Learning
Abstract: International Conference on Machine Learning (ICML), 2026 Paper / Link
Taming Momentum: Rethinking Optimizer States Through Low-Rank Approximation
Abstract: International Conference on Learning Representations (ICLR), Oral, 2026 Paper / Link
Stop Tracking Me! Proactive Defense Against Attribute Inference Attack in LLMs
Abstract: International Conference on Learning Representations (ICLR), 2026 Paper / Link
What If Consensus Lies? Selective-Complementary Reinforcement Learning at Test Time
Abstract: Annual Meeting of the Association for Computational Linguistics (ACL), 2026 Paper / Link / Code
Understanding and Mitigating Spurious Signal Amplification in Test-Time Reinforcement Learning
Abstract: Annual Meeting of the Association for Computational Linguistics (ACL), Findings, 2026 Paper / Link / Code
FedBST: Bilateral Self-Training for Unsupervised Federated Classification
Abstract: IEEE International Conference on Multimedia and Expo (ICME), 2026 Paper / Link
Refining Open-Vocabulary Semantic Segmentation via Regional Semantics and Visual Prototypes
Abstract: International Conference on Acoustics, Speech, and Signal Processing (ICASSP), 2026 Paper / Link
Learning Fair Domain Adaptation with Virtual Label Distribution
Abstract: International Conference on Acoustics, Speech, and Signal Processing (ICASSP), 2026 Paper / Link
A Comprehensive Survey on Test-Time Adaptation under Distribution Shifts
Abstract: Machine learning methods strive to acquire a robust model during the training process that can effectively generalize to test samples, even in the presence of distribution shifts. However, these methods often suffer from performance degradation due to unknown test distributions. Test-time adaptation (TTA), an emerging paradigm, has the potential to adapt a pre-trained model to unlabeled data during testing, before making predictions. Recent progress in this paradigm has highlighted the significant benefits of using unlabeled data to train self-adapted models prior to inference. In this survey, we categorize TTA into several distinct groups based on the form of test data, namely, test-time domain adaptation, test-time batch adaptation, and online test-time adaptation. For each category, we provide a comprehensive taxonomy of advanced algorithms and discuss various learning scenarios. Furthermore, we analyze relevant applications of TTA and discuss open challenges and promising areas for future research. For a comprehensive list of TTA methods, kindly refer to https://github.com/tim-learn/awesome-test-time-adaptation. International Journal of Computer Vision (IJCV), 2025 Paper / Link / Code
Sample Correlation for Fingerprinting Deep Face Recognition
Abstract: Face recognition has witnessed remarkable advancements in recent years, thanks to the development of deep learning techniques. However, an off-the-shelf face recognition model as a commercial service could be stolen by model stealing attacks, posing great threats to the rights of the model owner. Model fingerprinting, as a model stealing detection method, aims to verify whether a suspect model is stolen from the victim model, gaining more and more attention nowadays. Previous methods always utilize transferable adversarial examples as the model fingerprint, but this method is known to be sensitive to adversarial defense and transfer learning techniques. To address this issue, we consider the pairwise relationship between samples instead and propose a novel yet simple model stealing detection method based on SAmple Correlation (SAC). Specifically, we present SAC-JC that selects JPEG compressed samples as model inputs and calculates the correlation matrix among their model outputs. Extensive results validate that SAC successfully defends against various model stealing attacks in deep face recognition, encompassing face verification and face emotion recognition, exhibiting the highest performance in terms of AUC, p-value and F1 score. Furthermore, we extend our evaluation of SAC-JC to object recognition datasets including Tiny-ImageNet and CIFAR10, which also demonstrates the superior performance of SAC-JC to previous methods. International Journal of Computer Vision (IJCV), 2025 Paper / Link / Code
Out-of-Distribution Detection: A Task-Oriented Survey of Recent Advances
Abstract: ACM Computing Surveys (CSUR), 2025 Paper / Link / Code
The Illusion of Progress? A Critical Look at Test-Time Adaptation for Vision-Language Models
Abstract: NeurIPS Datasets and Benchmarks Track, 2025 Paper / Link / Code
LoRA-Pro: Are Low-Rank Adapters Properly Optimized?
Abstract: Low-rank adaptation, also known as LoRA, has emerged as a prominent method for parameter-efficient fine-tuning of foundation models. Despite its computational efficiency, LoRA still yields inferior performance compared to full fine-tuning. In this paper, we first uncover a fundamental connection between the optimization processes of LoRA and full fine-tuning: using LoRA for optimization is mathematically equivalent to full fine-tuning using a low-rank gradient for parameter updates. And this low-rank gradient can be expressed in terms of the gradients of the two low-rank matrices in LoRA. Leveraging this insight, we introduce LoRA-Pro, a method that enhances LoRA's performance by strategically adjusting the gradients of these low-rank matrices. This adjustment allows the low-rank gradient to more accurately approximate the full fine-tuning gradient, thereby narrowing the performance gap between LoRA and full fine-tuning. Furthermore, we theoretically derive the optimal solutions for adjusting the gradients of the low-rank matrices, applying them during fine-tuning in LoRA-Pro. We conduct extensive experiments across natural language understanding, dialogue generation, mathematical reasoning, code generation, and image classification tasks, demonstrating that LoRA-Pro substantially improves LoRA's performance, effectively narrowing the gap with full fine-tuning. International Conference on Learning Representations (ICLR), Spotlight, 2025 Paper / Link / Code
R-TPT: Improving Adversarial Robustness of Vision-Language Models through Test-Time Prompt Tuning
Abstract: Vision-language models (VLMs), such as CLIP, have gained significant popularity as foundation models, with numerous fine-tuning methods developed to enhance performance on downstream tasks. However, due to their inherent vulnerability and the common practice of selecting from a limited set of open-source models, VLMs suffer from a higher risk of adversarial attacks than traditional vision models. Existing defense techniques typically rely on adversarial fine-tuning during training, which requires labeled data and lacks of flexibility for downstream tasks. To address these limitations, we propose robust test-time prompt tuning (R-TPT), which mitigates the impact of adversarial attacks during the inference stage. We first reformulate the classic marginal entropy objective by eliminating the term that introduces conflicts under adversarial conditions, retaining only the pointwise entropy minimization. Furthermore, we introduce a plug-and-play reliability-based weighted ensembling strategy, which aggregates useful information from reliable augmented views to strengthen the defense. R-TPT enhances defense against adversarial attacks without requiring labeled training data while offering high flexibility for inference tasks. Extensive experiments on widely used benchmarks with various attacks demonstrate the effectiveness of R-TPT. IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025 Paper / Link / Code
Do We Really Need Curated Malicious Data for Safety Alignment in Multi-modal Large Language Models?
Abstract: Multi-modal large language models (MLLMs) have made significant progress, yet their safety alignment remains limited. Typically, current open-source MLLMs rely on the alignment inherited from their language module to avoid harmful generations. However, the lack of safety measures specifically designed for multi-modal inputs creates an alignment gap, leaving MLLMs vulnerable to vision-domain attacks such as typographic manipulation. Current methods utilize a carefully designed safety dataset to enhance model defense capability, while the specific knowledge or patterns acquired from the high-quality dataset remain unclear. Through comparison experiments, we find that the alignment gap primarily arises from data distribution biases, while image content, response quality, or the contrastive behavior of the dataset makes little contribution to boosting multi-modal safety. To further investigate this and identify the key factors in improving MLLM safety, we propose finetuning MLLMs on a small set of benign instruct-following data with responses replaced by simple, clear rejection sentences. Experiments show that, without the need for labor-intensive collection of high-quality malicious data, model safety can still be significantly improved, as long as a specific fraction of rejection data exists in the finetuning set, indicating the security alignment is not lost but rather obscured during multi-modal pretraining or instruction finetuning. Simply correcting the underlying data bias could narrow the safety gap in the vision domain. IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025 Paper / Link / Code
Cooperative Pseudo Labeling for Unsupervised Federated Classification
Abstract: International Conference on Computer Vision (ICCV), 2025 Paper / Link / Code
Protecting Model Adaptation from Trojans in the Unlabeled Data
Abstract: Model adaptation tackles the distribution shift problem with a pre-trained model instead of raw data, which has become a popular paradigm due to its great privacy protection. Existing methods always assume adapting to a clean target domain, overlooking the security risks of unlabeled samples. This paper for the first time explores the potential trojan attacks on model adaptation launched by well-designed poisoning target data. Concretely, we provide two trigger patterns with two poisoning strategies for different prior knowledge owned by attackers. These attacks achieve a high success rate while maintaining the normal performance on clean samples in the test stage. To defend against such backdoor injection, we propose a plug-and-play method named DiffAdapt, which can be seamlessly integrated with existing adaptation algorithms. Experiments across commonly used benchmarks and adaptation methods demonstrate the effectiveness of DiffAdapt. We hope this work will shed light on the safety of transfer learning with unlabeled data. AAAI Conference on Artificial Intelligence (AAAI), 2025 Paper / Link
Exploring Vacant Classes in Label-Skewed Federated Learning
Abstract: Label skews, characterized by disparities in local label distribution across clients, pose a significant challenge in federated learning. As minority classes suffer from worse accuracy due to overfitting on local imbalanced data, prior methods often incorporate class-balanced learning techniques during local training. Although these methods improve the mean accuracy across all classes, we observe that vacant classes-referring to categories absent from a client's data distribution-remain poorly recognized. Besides, there is still a gap in the accuracy of local models on minority classes compared to the global model. This paper introduces FedVLS, a novel approach to label-skewed federated learning that integrates both vacant-class distillation and logit suppression simultaneously. Specifically, vacant-class distillation leverages knowledge distillation during local training on each client to retain essential information related to vacant classes from the global model. Moreover, logit suppression directly penalizes network logits for non-label classes, effectively addressing misclassifications in minority classes that may be biased toward majority classes. Extensive experiments validate the efficacy of FedVLS, demonstrating superior performance compared to previous state-of-the-art (SOTA) methods across diverse datasets with varying degrees of label skews. AAAI Conference on Artificial Intelligence (AAAI), 2025 Paper / Link / Code
Uni-Layout: Integrating Human Feedback in Unified Layout Generation and Evaluation
Abstract: Layout generation plays a crucial role in enhancing both user experience and design efficiency. However, current approaches suffer from task-specific generation capabilities and perceptually misaligned evaluation metrics, leading to limited applicability and ineffective measurement. In this paper, we propose \textit{Uni-Layout}, a novel framework that achieves unified generation, human-mimicking evaluation and alignment between the two. For universal generation, we incorporate various layout tasks into a single taxonomy and develop a unified generator that handles background or element contents constrained tasks via natural language prompts. To introduce human feedback for the effective evaluation of layouts, we build \textit{Layout-HF100k}, the first large-scale human feedback dataset with 100,000 expertly annotated layouts. Based on \textit{Layout-HF100k}, we introduce a human-mimicking evaluator that integrates visual and geometric information, employing a Chain-of-Thought mechanism to conduct qualitative assessments alongside a confidence estimation module to yield quantitative measurements. For better alignment between the generator and the evaluator, we integrate them into a cohesive system by adopting Dynamic-Margin Preference Optimization (DMPO), which dynamically adjusts margins based on preference strength to better align with human judgments. Extensive experiments show that \textit{Uni-Layout} significantly outperforms both task-specific and general-purpose methods. ACM International Conference on Multimedia (ACM MM), 2025 Paper / Link / Code
Frustratingly Easy Feature Reconstruction for Out-of-Distribution Detection
Abstract: Chinese Conference on Pattern Recognition and Computer Vision (PRCV), 2025 Paper / Link / Code
An Enhanced Federated Prototype Learning Method under Domain Shift
Abstract: Chinese Conference on Pattern Recognition and Computer Vision (PRCV), 2025 Paper / Link
Understanding and Mitigating Dimensional Collapse in Federated Learning
Abstract: IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 2024 Paper / Link / Code
A Curriculum-style Self-Training Approach for Source-Free Semantic Segmentation
Abstract: Source-free domain adaptation has developed rapidly in recent years, where the well-trained source model is adapted to the target domain instead of the source data, offering the potential for privacy concerns and intellectual property protection. However, a number of feature alignment techniques in prior domain adaptation methods are not feasible in this challenging problem setting. Thereby, we resort to probing inherent domain-invariant feature learning and propose a curriculum-style self-training approach for source-free domain adaptive semantic segmentation. In particular, we introduce a curriculum-style entropy minimization method to explore the implicit knowledge from the source model, which fits the trained source model to the target data using certain information from easy-to-hard predictions. We then train the segmentation network by the proposed complementary curriculum-style self-training, which utilizes the negative and positive pseudo labels following the curriculum-learning manner. Although negative pseudo-labels with high uncertainty cannot be identified with the correct labels, they can definitely indicate absent classes. Moreover, we employ an information propagation scheme to further reduce the intra-domain discrepancy within the target domain, which could act as a standard post-processing method for the domain adaptation field. Furthermore, we extend the proposed method to a more challenging black-box source model scenario where only the source model's predictions are available. Extensive experiments validate that our method yields state-of-the-art performance on source-free semantic segmentation tasks for both synthetic-to-real and adverse conditions datasets. IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 2024 Paper / Link / Code
Learning Spatiotemporal Inconsistency via Thumbnail Layout for Face Deepfake Detection
Abstract: The deepfake threats to society and cybersecurity have provoked significant public apprehension, driving intensified efforts within the realm of deepfake video detection. Current video-level methods are mostly based on 3D CNNs resulting in high computational demands, although have achieved good performance. This paper introduces an elegantly simple yet effective strategy named Thumbnail Layout (TALL), which transforms a video clip into a pre-defined layout to realize the preservation of spatial and temporal dependencies. This transformation process involves sequentially masking frames at the same positions within each frame. These frames are then resized into sub-frames and reorganized into the predetermined layout, forming thumbnails. TALL is model-agnostic and has remarkable simplicity, necessitating only minimal code modifications. Furthermore, we introduce a graph reasoning block (GRB) and semantic consistency (SC) loss to strengthen TALL, culminating in TALL++. GRB enhances interactions between different semantic regions to capture semantic-level inconsistency clues. The semantic consistency loss imposes consistency constraints on semantic features to improve model generalization ability. Extensive experiments on intra-dataset, cross-dataset, diffusion-generated image detection, and deepfake generation method recognition show that TALL++ achieves results surpassing or comparable to the state-of-the-art methods, demonstrating the effectiveness of our approaches for various deepfake detection problems. International Journal of Computer Vision (IJCV), 2024 Paper / Link / Code
MAPS: A Noise-Robust Progressive Learning Approach for Source-Free Domain Adaptive Keypoint Detection
Abstract: Existing cross-domain keypoint detection methods always require accessing the source data during adaptation, which may violate the data privacy law and pose serious security concerns. Instead, this paper considers a realistic problem setting called source-free domain adaptive keypoint detection, where only the well-trained source model is provided to the target domain. For the challenging problem, we first construct a teacher-student learning baseline by stabilizing the predictions under data augmentation and network ensembles. Built on this, we further propose a unified approach, Mixup Augmentation and Progressive Selection (MAPS), to fully exploit the noisy pseudo labels of unlabeled target data during training. On the one hand, MAPS regularizes the model to favor simple linear behavior in-between the target samples via self-mixup augmentation, preventing the model from over-fitting to noisy predictions. On the other hand, MAPS employs the self-paced learning paradigm and progressively selects pseudo-labeled samples from 'easy' to 'hard' into the training process to reduce noise accumulation. Results on four keypoint detection datasets show that MAPS outperforms the baseline and achieves comparable or even better results in comparison to previous non-source-free counterparts. IEEE Transactions on Circuits and Systems for Video Technology (TCSVT), 2024 Paper / Link / Code
Towards Reliable Model Selection for Unsupervised Domain Adaptation: An Empirical Study and A Certified Baseline
Abstract: Selecting appropriate hyperparameters is crucial for unlocking the full potential of advanced unsupervised domain adaptation (UDA) methods in unlabeled target domains. Although this challenge remains under-explored, it has recently garnered increasing attention with the proposals of various model selection methods. Reliable model selection should maintain performance across diverse UDA methods and scenarios, especially avoiding highly risky worst-case selections—selecting the model or hyperparameter with the worst performance in the pool. \textit{Are existing model selection methods reliable and versatile enough for different UDA tasks?} In this paper, we provide a comprehensive empirical study involving 8 existing model selection approaches to answer this question. Our evaluation spans 12 UDA methods across 5 diverse UDA benchmarks and 5 popular UDA scenarios. Surprisingly, we find that none of these approaches can effectively avoid the worst-case selection. In contrast, a simple but overlooked ensemble-based selection approach, which we call EnsV, is both theoretically and empirically certified to avoid the worst-case selection, ensuring high reliability. Additionally, EnsV is versatile for various practical but challenging UDA scenarios, including validation of open-partial-set UDA and source-free UDA. Finally, we call for more attention to the reliability of model selection in UDA: avoiding the worst-case is as significant as achieving peak selection performance and should not be overlooked when developing new model selection methods. NeurIPS Datasets and Benchmarks Track, 2024 Paper / Link / Code
Realistic Unsupervised CLIP Fine-tuning with Universal Entropy Optimization
Abstract: The emergence of vision-language models, such as CLIP, has spurred a significant research effort towards their application for downstream supervised learning tasks. Although some previous studies have explored the unsupervised fine-tuning of CLIP, they often rely on prior knowledge in the form of class names associated with ground truth labels. This paper explores a realistic unsupervised fine-tuning scenario, considering the presence of out-of-distribution samples from unknown classes within the unlabeled data. In particular, we focus on simultaneously enhancing out-of-distribution detection and the recognition of instances associated with known classes. To tackle this problem, we present a simple, efficient, and effective approach called Universal Entropy Optimization (UEO). UEO leverages sample-level confidence to approximately minimize the conditional entropy of confident instances and maximize the marginal entropy of less confident instances. Apart from optimizing the textual prompt, UEO incorporates optimization of channel-wise affine transformations within the visual branch of CLIP. Extensive experiments across 15 domains and 4 different types of prior knowledge validate the effectiveness of UEO compared to baseline methods. International Conference on Machine Learning (ICML), Spotlight, 2024 Paper / Link / Code
Connecting the Dots: Collaborative Fine-tuning for Black-Box Vision-Language Models
Abstract: With the emergence of pretrained vision-language models (VLMs), considerable efforts have been devoted to fine-tuning them for downstream tasks. Despite the progress made in designing efficient fine-tuning methods, such methods require access to the model’s parameters, which can be challenging as model owners often opt to provide their models as a black box to safeguard model ownership. This paper proposes a Collaborative Fine-Tuning (CraFT) approach for fine-tuning black-box VLMs to downstream tasks, where one only has access to the input prompts and the output predictions of the model. CraFT comprises two modules, a prompt generation module for learning text prompts and a prediction refinement module for enhancing output predictions in residual style. Additionally, we introduce an auxiliary prediction-consistent loss to promote consistent optimization across these modules. These modules are optimized by a novel collaborative training algorithm. Extensive experiments on few-shot classification over 15 datasets demonstrate the superiority of CraFT. The results show that CraFT achieves a decent gain of about 12% with 16-shot datasets and only 8,000 queries. Moreover, CraFT trains faster and uses only about 1/80 of the memory footprint for deployment, while sacrificing only 1.62% compared to the white-box method. International Conference on Machine Learning (ICML), 2024 Paper / Link / Code
Pseudo-Calibration: Improving Predictive Uncertainty Estimation in Unsupervised Domain Adaptation
Abstract: Unsupervised domain adaptation (UDA) has seen substantial efforts to improve model accuracy for an unlabeled target domain with the help of a labeled source domain. However, UDA models often exhibit poorly calibrated predictive uncertainty on target data, a problem that remains under-explored and poses risks in safety-critical UDA applications. The calibration problem in UDA is particularly challenging due to the absence of labeled target data and severe distribution shifts between domains. In this paper, we approach UDA calibration as a target-domain-specific unsupervised problem, different from mainstream solutions based on covariate shift. We introduce Pseudo-Calibration (PseudoCal), a novel post-hoc calibration framework. Our innovative use of inference-stage mixup synthesizes a labeled pseudo-target set capturing the structure of the real unlabeled target data. This turns the unsupervised calibration problem into a supervised one, easily solvable with temperature scaling. Extensive empirical evaluations across 5 diverse UDA scenarios involving 10 UDA methods consistently demonstrate the superior performance and versatility of PseudoCal over existing solutions. International Conference on Machine Learning (ICML), 2024 Paper / Link / Code
Towards Eliminating Hard Label Constraints in Gradient Inversion Attacks
Abstract: Gradient inversion attacks aim to reconstruct local training data from intermediate gradients exposed in the federated learning framework. Despite successful attacks, all previous methods, starting from reconstructing a single data point and then relaxing the single-image limit to batch level, are only tested under hard label constraints. Even for single-image reconstruction, we still lack an analysis-based algorithm to recover augmented soft labels. In this work, we change the focus from enlarging batchsize to investigating the hard label constraints, considering a more realistic circumstance where label smoothing and mixup techniques are used in the training process. In particular, we are the first to initiate a novel algorithm to simultaneously recover the ground-truth augmented label and the input feature of the last fully-connected layer from single-input gradients, and provide a necessary condition for any analytical-based label recovery methods. Extensive experiments testify to the label recovery accuracy, as well as the benefits to the following image reconstruction. We believe soft labels in classification tasks are worth further attention in gradient inversion attacks. International Conference on Learning Representations (ICLR), 2024 Paper / Link / Code
A Hard-to-Beat Baseline for Training-free CLIP-based Adaptation
Abstract: Contrastive Language-Image Pretraining (CLIP) has gained popularity for its remarkable zero-shot capacity. Recent research has focused on developing efficient fine-tuning methods, such as prompt learning and adapter, to enhance CLIP's performance in downstream tasks. However, these methods still require additional training time and computational resources, which is undesirable for devices with limited resources. In this paper, we revisit a classical algorithm, Gaussian Discriminant Analysis (GDA), and apply it to the downstream classification of CLIP. Typically, GDA assumes that features of each class follow Gaussian distributions with identical covariance. By leveraging Bayes' formula, the classifier can be expressed in terms of the class means and covariance, which can be estimated from the data without the need for training. To integrate knowledge from both visual and textual modalities, we ensemble it with the original zero-shot classifier within CLIP. Extensive results on 17 datasets validate that our method surpasses or achieves comparable results with state-of-the-art methods on few-shot classification, imbalanced learning, and out-of-distribution generalization. In addition, we extend our method to base-to-new generalization and unsupervised learning, once again demonstrating its superiority over competing approaches. International Conference on Learning Representations (ICLR), 2024 Paper / Link / Code
Backdoor Defense via Test-Time Detecting and Repairing
Abstract: Deep neural networks have played a crucial part in many critical domains such as autonomous driving face recognition and medical diagnosis. However deep neural networks are facing security threats from backdoor attacks and can be manipulated into attacker-decided behaviors by the backdoor attacker. To defend the backdoor prior research has focused on using clean data to remove backdoor attacks before model deployment. In this paper we investigate the possibility of defending against backdoor attacks by utilizing test-time partially poisoned data to remove the backdoor from the model. To address the problem a two-stage method TTBD is proposed. In the first stage we propose a backdoor sample detection method DDP to identify poisoned samples from a batch of mixed partially poisoned samples. Once the poisoned samples are detected we employ Shapley estimation to calculate the contribution of each neuron's significance in the network locate the poisoned neurons and prune them to remove backdoor in the models. Our experiments demonstrate that TTBD removes the backdoor successfully with only a batch of partially poisoned data across different model architectures and datasets against different types of backdoor attacks. IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024 Paper / Link
Outlier-Aware Test-Time Adaptation with Stable Memory Replay
Abstract: Test-time adaptation (TTA) aims to address the distribution shift between the training and test data with only unlabeled data at test time. Existing TTA methods often focus on improving recognition performance specifically for test data associated with classes in the training set. However, during the open-world inference process, there are inevitably test data instances from unknown classes, commonly referred to as outliers. This paper pays attention to the problem that conducts both sample recognition and outlier rejection during inference while outliers exist. To address this problem, we propose a new approach called STAble Memory rePlay (STAMP), which performs optimization over a stable memory bank instead of the risky mini-batch. In particular, the memory bank is dynamically updated by selecting low-entropy and label-consistent samples in a class-balanced manner. In addition, we develop a self-weighted entropy minimization strategy that assigns higher weight to low-entropy samples. Extensive results demonstrate that STAMP outperforms existing TTA methods in terms of both recognition and outlier detection performance. European Conference on Computer Vision (ECCV), 2024 Paper / Link / Code
Masked Relation Learning for DeepFake Detection
Abstract: DeepFake detection aims to differentiate falsified faces from real ones. Most approaches formulate it as a binary classification problem by solely mining the local artifacts and inconsistencies of face forgery, which neglect the relation across local regions. Although several recent works explore local relation learning for DeepFake detection, they overlook the propagation of relational information and lead to limited performance gains. To address these issues, this paper provides a new perspective by formulating DeepFake detection as a graph classification problem, in which each facial region corresponds to a vertex. But relational information with large redundancy hinders the expressiveness of graphs. Inspired by the success of masked modeling, we propose Masked Relation Learning which reduces the redundancy to learn informative relational features. Specifically, a spatiotemporal attention module is exploited to learn attention features of multiple facial regions. A relation learning module masks partial correlations between regions to reduce redundancy and then propagates the relational information across regions to capture the irregularity from a global view of the graph. We empirically discover that a moderate masking rate (e.g., 50%) brings the best performance gain. Experiments verify the effectiveness of Masked Relation Learning and demonstrate that Masked Relation Learning outperforms the state of the art by 2% AUC on the cross-dataset DeepFake video detection. IEEE Transactions on Information Forensics and Security (TIFS), 2023 Paper / Link / Code
ProxyMix: Proxy-based Mixup Training with Label Refinery for Source-Free Domain Adaptation
Abstract: Due to privacy concerns and data transmission issues, Source-free Unsupervised Domain Adaptation (SFDA) has gained popularity. It exploits pre-trained source models, rather than raw source data for target learning, to transfer knowledge from a labeled source domain to an unlabeled target domain. Existing methods solve this problem typically with additional parameters or noisy pseudo labels, and we propose an effective method named Proxy-based Mixup training with label refinery (ProxyMix) to avoid these drawbacks. To avoid additional parameters and leverages information in the source model, ProxyMix defines classifier weights as class prototypes and creates a class-balanced proxy source domain using nearest neighbors of the prototypes. To improve the reliability of pseudo labels, we further propose the frequency-weighted aggregation strategy to generate soft pseudo labels for unlabeled target data. Our strategy utilizes target features' internal structure, increases weights of low-frequency class samples, and aligns the proxy and target domains using inter- and intra-domain mixup regularization. This mitigates the negative impact of noisy labels. Experiments on three 2D image and 3D point cloud object recognition benchmarks demonstrate that ProxyMix yields state-of-the-art performance for source-free UDA tasks. Neural Networks (NN), 2023 Paper / Link / Code
Reciprocal Normalization for Domain Adaptation
Abstract: Batch normalization (BN) is widely used in modern deep neural networks, which has been shown to represent the domain-related knowledge, and thus is ineffective for cross-domain tasks like unsupervised domain adaptation (UDA). Existing BN variant methods aggregate source and target domain knowledge in the same channel in normalization module. However, the misalignment between the features of corresponding channels across domains often leads to a sub-optimal transferability. In this paper, we exploit the cross-domain relation and propose a novel normalization method, Reciprocal Normalization (RN). Specifically, RN first presents a Reciprocal Compensation (RC) module to acquire the compensatory for each channel in both domains based on the cross-domain channel-wise correlation. Then RN develops a Reciprocal Aggregation (RA) module to adaptively aggregate the feature with its cross-domain compensatory components. As an alternative to BN, RN is more suitable for UDA problems and can be easily integrated into popular domain adaptation methods. Experiments show that the proposed RN outperforms existing normalization counterparts by a large margin and helps state-of-the-art adaptation approaches achieve better results. Pattern Recognition (PR), 2023 Paper / Link / Code
Color-Unrelated Head-Shoulder Networks for Fine-Grained Person Re-identification
Abstract: Person re-identification (re-id) attempts to match pedestrian images with the same identity across non-overlapping cameras. Existing methods usually study person re-id by learning discriminative features based on the clothing attributes (e.g., color, texture). However, the clothing appearance is not sufficient to distinguish different persons especially when they are in similar clothes, which is known as the fine-grained (FG) person re-id problem. By contrast, this paper proposes to exploit the color-unrelated feature along with the head-shoulder feature for FG person re-id. Specifically, a color-unrelated head-shoulder network (CUHS) is developed, which is featured in three aspects: (1) It consists of a lightweight head-shoulder segmentation layer for localizing the head-shoulder region and learning the corresponding feature. (2) It exploits instance normalization (IN) for learning color-unrelated features. (3) As IN inevitably reduces inter-class differences, we propose to explore richer visual cues for IN by an attention exploration mechanism to ensure high discrimination. We evaluate our model on the FG-reID, Market1501, and DukeMTMC-reID datasets, and the results show that CUHS surpasses previous methods on both the FG and conventional person re-id problems. ACM Transactions on Multimedia Computing, Communications, and Application (TOMM), 2023 Paper / Link
Towards Understanding and Mitigating Dimensional Collapse in Heterogeneous Federated Learning
Abstract: Federated learning aims to train models collaboratively across different clients without sharing data for privacy considerations. However, one major challenge for this learning paradigm is the data heterogeneity problem, which refers to the discrepancies between the local data distributions among various clients. To tackle this problem, we first study how data heterogeneity affects the representations of the globally aggregated models. Interestingly, we find that heterogeneous data results in the global model suffering from severe dimensional collapse, in which representations tend to reside in a lower-dimensional space instead of the ambient space. Moreover, we observe a similar phenomenon on models locally trained on each client and deduce that the dimensional collapse on the global model is inherited from local models. In addition, we theoretically analyze the gradient flow dynamics to shed light on how data heterogeneity result in dimensional collapse for local models. To remedy this problem caused by the data heterogeneity, we propose FedDecorr, a novel method that can effectively mitigate dimensional collapse in federated learning. Specifically, FedDecorr applies a regularization term during local training that encourages different dimensions of representations to be uncorrelated. FedDecorr, which is implementation-friendly and computationally-efficient, yields consistent improvements over baselines on standard benchmark datasets. International Conference on Learning Representations (ICLR), 2023 Paper / Link / Code
Free Lunch for Domain Adversarial Training: Environment Label Smoothing
Abstract: A fundamental challenge for machine learning models is how to generalize learned models for out-of-distribution (OOD) data. Among various approaches, exploiting invariant features by Domain Adversarial Training (DAT) received widespread attention. Despite its success, we observe training instability from DAT, mostly due to over-confident domain discriminator and environment label noise. To address this issue, we proposed Environment Label Smoothing (ELS), which encourages the discriminator to output soft probability, which thus reduces the confidence of the discriminator and alleviates the impact of noisy environment labels. We demonstrate, both experimentally and theoretically, that ELS can improve training stability, local convergence, and robustness to noisy environment labels. By incorporating ELS with DAT methods, we are able to yield state-of-art results on a wide range of domain generalization/adaptation tasks, particularly when the environment labels are highly noisy. International Conference on Learning Representations (ICLR), 2023 Paper / Link / Code
Mixed Samples as Probes for Unsupervised Model Selection in Domain Adaptation
Abstract: Unsupervised domain adaptation (UDA) has been widely applied in improving model generalization on unlabeled target data. However, accurately selecting the best UDA model for the target domain is challenging due to the absence of labeled target data and domain distribution shifts. Traditional model selection approaches involve training extra models with source data to estimate the target validation risk. Recent studies propose practical methods that are based on measuring various properties of model predictions on target data. Although effective for some UDA models, these methods often lack stability and may lead to poor selections for other UDA models. In this paper, we present MixVal, an innovative model selection method that operates solely with unlabeled target data during inference. MixVal leverages mixed target samples with pseudo labels to directly probe the learned target structure by each UDA model. Specifically, MixVal employs two distinct types of probes: the intra-cluster mixed samples for evaluating neighborhood density and the inter-cluster mixed samples for investigating the classification boundary. With this comprehensive probing strategy, MixVal elegantly combines the strengths of two state-of-the-art model selection methods, Entropy and SND. We extensively evaluate MixVal on 11 UDA methods across 4 adaptation settings, including classification and segmentation tasks. Experimental results consistently demonstrate that MixVal achieves state-of-the-art performance and maintains exceptional stability in model selection. Annual Conference on Neural Information Processing Systems (NeurIPS), 2023 Paper / Link / Code
Mind the Label Shift for Augmentation-based Graph Out-of-Distribution Generalization
Abstract: Out-of-distribution (OOD) generalization is an important issue for Graph Neural Networks (GNNs). Recent works employ different graph editions to generate augmented environments and learn an invariant GNN for generalization. However, the graph structural edition inevitably alters the graph label. This causes the label shift in augmentations and brings inconsistent predictive relationships among augmented environments. To address this issue, we propose \textbf{LiSA}, which generates label-invariant augmentations to facilitate graph OOD generalization. Instead of resorting to graph editions, LiSA exploits \textbf{L}abel-\textbf{i}nvariant \textbf{S}ubgraphs of the training graphs to construct \textbf{A}ugmented environments. Specifically, LiSA first designs the variational subgraph generators to efficiently extract locally predictive patterns and construct multiple label-invariant subgraphs. Then, the subgraphs produced by different generators are collected to build different augmented environments. To promote diversity among augmented environments, LiSA further introduces a tractable energy-based regularization to enlarge pair-wise distances between the distributions of environments. In this manner, LiSA generates diverse augmented environments with a consistent predictive relationship to facilitate learning an invariant GNN. Extensive experiments on node-level and graph-level OOD benchmarks show that LiSA achieves impressive generalization performance with different GNN backbones. IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2023 Paper / Link / Code
AdaptGuard: Defending Against Universal Attacks for Model Adaptation
Abstract: Model adaptation aims at solving the domain transfer problem under the constraint of only accessing the pretrained source models. With the increasing considerations of data privacy and transmission efficiency, this paradigm has been gaining recent popularity. This paper studies the vulnerability to universal attacks transferred from the source domain during model adaptation algorithms due to the existence of the malicious providers. We explore both universal adversarial perturbations and backdoor attacks as loopholes on the source side and discover that they still survive in the target models after adaptation. To address this issue, we propose a model preprocessing framework, named AdaptGuard, to improve the security of model adaptation algorithms. AdaptGuard avoids direct use of the risky source parameters through knowledge distillation and utilizes the pseudo adversarial samples under adjusted radius to enhance the robustness. AdaptGuard is a plug-and-play module that requires neither robust pretrained models nor any changes for the following model adaptation algorithms. Extensive results on three commonly used datasets and two popular adaptation methods validate that AdaptGuard can effectively defend against universal attacks and maintain clean accuracy in the target domain simultaneously. We hope this research will shed light on the safety and robustness of transfer learning. International Conference on Computer Vision (ICCV), 2023 Paper / Link
Improving Zero-Shot Generalization for CLIP with Synthesized Prompts
Abstract: With the growing interest in pretrained vision-language models like CLIP, recent research has focused on adapting these models to downstream tasks. Despite achieving promising results, most existing methods require labeled data for all classes, which may not hold in real-world applications due to the long tail and Zipf's law. For example, some classes may lack labeled data entirely, such as emerging concepts. To address this problem, we propose a plug-and-play generative approach called \textbf{S}ynt\textbf{H}es\textbf{I}zed \textbf{P}rompts~(\textbf{SHIP}) to improve existing fine-tuning methods. Specifically, we follow variational autoencoders to introduce a generator that reconstructs the visual features by inputting the synthesized prompts and the corresponding class names to the textual encoder of CLIP. In this manner, we easily obtain the synthesized features for the remaining label-only classes. Thereafter, we fine-tune CLIP with off-the-shelf methods by combining labeled and synthesized features. Extensive experiments on base-to-new generalization, cross-dataset transfer learning, and generalized zero-shot learning demonstrate the superiority of our approach. International Conference on Computer Vision (ICCV), 2023 Paper / Link / Code
Informative Data Mining for One-shot Cross-Domain Semantic Segmentation
Abstract: Contemporary domain adaptation offers a practical solution for achieving cross-domain transfer of semantic segmentation between labelled source data and unlabeled target data. These solutions have gained significant popularity; however, they require the model to be retrained when the test environment changes. This can result in unbearable costs in certain applications due to the time-consuming training process and concerns regarding data privacy. One-shot domain adaptation methods attempt to overcome these challenges by transferring the pre-trained source model to the target domain using only one target data. Despite this, the referring style transfer module still faces issues with computation cost and over-fitting problems. To address this problem, we propose a novel framework called Informative Data Mining (IDM) that enables efficient one-shot domain adaptation for semantic segmentation. Specifically, IDM provides an uncertainty-based selection criterion to identify the most informative samples, which facilitates quick adaptation and reduces redundant training. We then perform a model adaptation method using these selected samples, which includes patch-wise mixing and prototype-based information maximization to update the model. This approach effectively enhances adaptation and mitigates the overfitting problem. In general, we provide empirical evidence of the effectiveness and efficiency of IDM. Our approach outperforms existing methods and achieves a new state-of-the-art one-shot performance of 56.7\%/55.4\% on the GTA5/SYNTHIA to Cityscapes adaptation tasks, respectively. International Conference on Computer Vision (ICCV), 2023 Paper / Link / Code
TALL: Thumbnail Layout for Deepfake Video Detection
Abstract: The growing threats of deepfakes to society and cybersecurity have raised enormous public concerns, and increasing efforts have been devoted to this critical topic of deepfake video detection.
Existing video methods achieve good performance but are computationally intensive.
This paper introduces a simple yet effective strategy named Thumbnail Layout (TALL), which transforms a video clip into a pre-defined layout to realize the preservation of spatial and temporal dependencies.
Specifically, consecutive frames are masked in a fixed position in each frame to improve generalization, then resized to sub-images and rearranged into a pre-defined layout as the thumbnail.
TALL is model-agnostic and extremely simple by only modifying a few lines of code.
Inspired by the success of vision transformers, we incorporate TALL into Swin Transformer, forming an efficient and effective method TALL-Swin.
Extensive experiments on intra-dataset and cross-dataset validate the validity and superiority of TALL and SOTA TALL-Swin.
TALL-Swin achieves 90.79$\%$ AUC on the challenging cross-dataset task, FaceForensics++ $\to$ Celeb-DF.
International Conference on Computer Vision (ICCV), 2023 Paper / Link / Code
Domain-Specific Risk Minimization for Domain Generalization
Abstract: Learning a domain-invariant representation has become one of the most popular approaches for domain adaptation/generalization. In this paper, we show that the invariant representation may not be sufficient to guarantee a good generalization, where the labeling function shift should be taken into consideration. Inspired by this, we first derive a new generalization upper bound on the empirical risk that explicitly considers the labeling function shift. We then propose Domain-specific Risk Minimization (DRM), which can model the distribution shifts of different domains separately and select the most appropriate one for the target domain. Extensive experiments on four popular domain generalization datasets, CMNIST, PACS, VLCS, and DomainNet, demonstrate the effectiveness of the proposed \abbr for domain generalization with the following advantages: 1) it significantly outperforms competitive baselines; 2) it enables either comparable or superior accuracies on all training domains comparing to vanilla empirical risk minimization (ERM); 3) it remains very simple and efficient during training, and 4) it is complementary to invariant learning approaches. ACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD), 2023 Paper / Link
Rumor Detection with Diverse Counterfactual Evidence
Abstract: Due to the growth in use of social media, fake news can cause serious problems in society, which are harmful to individuals or communities. Therefore, the researches on timely and effective detection of rumors have aroused lots of interest in both academia and industry, leading to the widespread research on rumor detection. Most existing methods have attempted to integrate graph neural networks (GNNs) with rumor detection to explore the post propagation patterns. However, these methods have overlooked the explanations for GNNs and are not counterfactual in nature, which influences the generalization and detection ability of models. In this paper, we propose a Diverse Counterfactual Evidence framework for rumor detection, named as DiCE, for interpretable evidence generation. Specifically, a subgraph generation strategy based on Top-K Nodes Sampling is proposed to provide interpretability for each event graph. Generally, the counterfactual evidence refers to the prediction changes when a perturbation is added to the event graph. We then present the counterfactual evidence by removing the set of nodes identified by an explanation from the event graph. Finally, a diversity loss with Determinantal Point Processes (DPP)-inspired loss is proposed to ensure the diversity of multiple pieces of evidence. Extensive experiments on two public datasets show the superior performance of our method. Our code is available at https://anonymous.4open.science/r/DiCE-2B40. ACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD), 2023 Paper / Link / Code
Exploiting Semantic Attributes for Transductive Zero-shot Learning
Abstract: Zero-shot learning (ZSL) aims to recognize unseen classes by generalizing the relation between visual features and semantic attributes learned from the seen classes. A recent paradigm called transductive zero-shot learning further leverages unlabeled unseen data during training and has obtained impressive results. These methods always synthesize unseen features from attributes through a generative adversarial network to mitigate the bias towards seen classes. However, they neglect the semantic information in the unlabeled unseen data and thus fail to generate high-fidelity attribute-consistent unseen features. To address this issue, we present a novel transductive ZSL method that produces semantic attributes of the unseen data and imposes them on the generative process. In particular, we first train an attribute decoder that learns the mapping from visual features to semantic attributes. Then, from the attribute decoder, we obtain pseudo-attributes of unlabeled data and integrate them into the generative model, which helps capture the detailed differences within unseen classes so as to synthesize more discriminative features. Experiments on five standard benchmarks show that our method yields state-of-the-art results for zero-shot learning. International Conference on Acoustics, Speech, and Signal Processing (ICASSP), 2023 Paper / Link / Code
MODIFY: Model-driven Face Stylization without Style Images
Abstract: Existing face stylization methods always acquire the presence of the target (style) domain during the translation process, which violates privacy regulations and limits their applicability in real-world systems. To address this issue, we propose a new method called MODel-drIven Face stYlization (MODIFY), which relies on the generative model to bypass the dependence of the target images. Briefly, MODIFY first trains a generative model in the target domain and then translates a source input to the target domain via the provided style model. To preserve the multimodal style information, MODIFY further introduces an additional remapping network, mapping a known continuous distribution into the encoder's embedding space. During translation in the source domain, MODIFY fine-tunes the encoder module within the target style-persevering model to capture the content of the source input as precisely as possible. Our method is extremely simple and satisfies versatile training modes for face stylization, \textit{i.e.}, offline, online, and test-time training. Experimental results on several different datasets validate the effectiveness of MODIFY for unsupervised face stylization. International Conference on Acoustics, Speech, and Signal Processing (ICASSP), 2023 Paper / Link / Code
Source Data-absent Unsupervised Domain Adaptation through Hypothesis Transfer and Labeling Transfer
Abstract: Unsupervised domain adaptation (UDA) aims to transfer knowledge from a related but different well-labeled source domain to a new unlabeled target domain. Most existing UDA methods require access to the source data, and thus are not applicable when the data are confidential and not shareable due to privacy concerns. This paper aims to tackle a realistic setting with only a classification model available trained over, instead of accessing to, the source data. To effectively utilize the source model for adaptation, we propose a novel approach called Source HypOthesis Transfer (SHOT), which learns the feature extraction module for the target domain by fitting the target data features to the frozen source classification module (representing classification hypothesis). Specifically, SHOT exploits both information maximization and self-supervised learning for the feature extraction module learning to ensure the target features are implicitly aligned with the features of unseen source data via the same hypothesis. Furthermore, we propose a new labeling transfer strategy, which separates the target data into two splits based on the confidence of predictions (labeling information), and then employ semi-supervised learning to improve the accuracy of less-confident predictions in the target domain. We denote labeling transfer as SHOT++ if the predictions are obtained by SHOT. Extensive experiments on both digit classification and object recognition tasks show that SHOT and SHOT++ achieve results surpassing or comparable to the state-of-the-arts, demonstrating the effectiveness of our approaches for various visual domain adaptation problems. IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 2022 Paper / Appendix / Link / Code
Learning Feature Recovery Transformer for Occluded Person Re-identification
Abstract: One major issue that challenges person re-identification (Re-ID) is the ubiquitous occlusion over the captured persons. There are two main challenges for the occluded person Re-ID problem, i.e. , the interference of noise during feature matching and the loss of pedestrian information brought by the occlusions. In this paper, we propose a new approach called Feature Recovery Transformer (FRT) to address the two challenges simultaneously, which mainly consists of visibility graph matching and feature recovery transformer. To reduce the interference of the noise during feature matching, we mainly focus on visible regions that appear in both images and develop a visibility graph to calculate the similarity. In terms of the second challenge, based on the developed graph similarity, for each query image, we propose a recovery transformer that exploits the feature sets of its k -nearest neighbors in the gallery to recover the complete features. Extensive experiments across different person Re-ID datasets, including occluded, partial and holistic datasets, demonstrate the effectiveness of FRT. Specifically, FRT significantly outperforms state-of-the-art results by at least 6.2% Rank- 1 accuracy and 7.2% mAP scores on the challenging Occluded-Duke dataset. IEEE Transactions on Image Processing (TIP), 2022 Paper / Link / Code
Heterogeneous Face Recognition via Face Synthesis with Identity-Attribute Disentanglement
Abstract: Heterogeneous Face Recognition (HFR) aims to match faces across different domains (e.g., visible to near-infrared images), which has been widely applied in authentication and forensics scenarios. However, HFR is a challenging problem because of the large cross-domain discrepancy, limited heterogeneous data pairs, and large variation of facial attributes. To address these challenges, we propose a new HFR method from the perspective of heterogeneous data augmentation, named Face Synthesis with Identity-Attribute Disentanglement (FSIAD). Firstly, the identity-attribute disentanglement (IAD) decouples face images into identity-related representations and identity-unrelated representations (called attributes), and then decreases the correlation between identities and attributes. Secondly, we devise a face synthesis module (FSM) to generate a large number of images with stochastic combinations of disentangled identities and attributes for enriching the attribute diversity of synthetic images. Both the original images and the synthetic ones are utilized to train the HFR network for tackling the challenges and improving the performance of HFR. Extensive experiments on five HFR databases validate that FSIAD obtains superior performance than previous HFR approaches. Particularly, FSIAD obtains 4.8% improvement over state of the art in terms of VR@FAR=0.01% on LAMP-HQ, the largest HFR database so far. IEEE Transactions on Information Forensics and Security (TIFS), 2022 Paper / Link
Are You Stealing My Model? Sample Correlation for Fingerprinting Deep Neural Networks
Abstract: An off-the-shelf model as a commercial service could be stolen by model stealing attacks, posing great threats to the rights of the model owner. Model fingerprinting aims to verify whether a suspect model is stolen from the victim model, which gains more and more attention nowadays. Previous methods always leverage the transferable adversarial examples as the model fingerprint, which is sensitive to adversarial defense or transfer learning scenarios. To address this issue, we consider the pairwise relationship between samples instead and propose a novel yet simple model stealing detection method based on SAmple Correlation (SAC). Specifically, we present SAC-w that selects wrongly classified normal samples as model inputs and calculates the mean correlation among their model outputs. To reduce the training time, we further develop SAC-m that selects CutMix Augmented samples as model inputs, without the need for training the surrogate models or generating adversarial examples. Extensive results validate that SAC successfully defends against various model stealing attacks, even including adversarial training or transfer learning, and detects the stolen models with the best performance in terms of AUC across different datasets and model architectures. Annual Conference on Neural Information Processing Systems (NeurIPS), 2022 Paper / Link / Code
DINE: Domain Adaptation from Single and Multiple Black-box Predictors
Abstract: To ease the burden of labeling, unsupervised domain adaptation (UDA) aims to transfer knowledge in previous and related labeled datasets (sources) to a new unlabeled dataset (target). Despite impressive progress, prior methods always need to access the raw source data and develop data-dependent alignment approaches to recognize the target samples in a transductive learning manner, which may raise privacy concerns from source individuals. Several recent studies resort to an alternative solution by exploiting the well-trained white-box model from the source domain, yet, it may still leak the raw data through generative adversarial learning. This paper studies a practical and interesting setting for UDA, where only black-box source models (i.e., only network predictions are available) are provided during adaptation in the target domain. To solve this problem, we propose a new two-step knowledge adaptation framework called DIstill and fine-tuNE (DINE). Taking into consideration the target data structure, DINE first distills the knowledge from the source predictor to a customized target model, then fine-tunes the distilled model to further fit the target domain. Besides, neural networks are not required to be identical across domains in DINE, even allowing effective adaptation on a low-resource device. Empirical results on three UDA scenarios (i.e., single-source, multi-source, and partial-set) confirm that DINE achieves highly competitive performance compared to state-of-the-art data-dependent approaches. IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Oral, 2022 Paper / Link / Code / Slides
Mimicking the Oracle: An Initial Phase Decorrelation Approach for Class Incremental Learning
Abstract: Class Incremental Learning (CIL) aims at learning a multi-class classifier in a phase-by-phase manner, in which only data of a subset of the classes are provided at each phase. Previous works mainly focus on mitigating forgetting in phases after the initial one. However, we find that improving CIL at its initial phase is also a promising direction. Specifically, we experimentally show that directly encouraging CIL Learner at the initial phase to output similar representations as the model jointly trained on all classes can greatly boost the CIL performance. Motivated by this, we study the difference between a naïvely-trained initial-phase model and the oracle model. Specifically, since one major difference between these two models is the number of training classes, we investigate how such difference affects the model representations. We find that, with fewer training classes, the data representations of each class lie in a long and narrow region; with more training classes, the representations of each class scatter more uniformly. Inspired by this observation, we propose Class-wise Decorrelation (CwD) that effectively regularizes representations of each class to scatter more uniformly, thus mimicking the model jointly trained with all classes (i.e., the oracle model). Our CwD is simple to implement and easy to plug into existing methods. Extensive experiments on various benchmark datasets show that CwD consistently and significantly improves the performance of existing state-of-the-art methods by around 1\% to 3\%. Code will be released. IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022 Paper / Link / Code
Mimicking Embedding via oThers' Aggregation for Generalizable Person Re-identification
Abstract: Domain generalizable (DG) person re-identification (ReID) aims to test across unseen domains without access to the target domain data at training time, which is a realistic but challenging problem. In contrast to methods assuming an identical model for different domains, Mixture of Experts (MoE) exploits multiple domain-specific networks for leveraging complementary information between domains, obtaining impressive results. However, prior MoE-based DG ReID methods suffer from a large model size with the increase of the number of source domains, and most of them overlook the exploitation of domain-invariant characteristics. To handle the two issues above, this paper presents a new approach called Mimic Embedding via adapTive Aggregation (META) for DG person ReID. To avoid the large model size, experts in META do not adopt a branch network for each source domain but share all the parameters except for the batch normalization layers. Besides multiple experts, META leverages Instance Normalization (IN) and introduces it into a global branch to pursue invariant features across domains. Meanwhile, META considers the relevance of an unseen target sample and source domains via normalization statistics and develops an aggregation module to adaptively integrate multiple experts for mimicking unseen target domain. Benefiting from a proposed consistency loss and an episodic training algorithm, META is expected to mimic embedding for a truly unseen target domain. Extensive experiments verify that META surpasses state-of-the-art DG person ReID methods by a large margin. European Conference on Computer Vision (ECCV), 2022. Paper / Link / Code
Diagnostic Classification for Human Autism and Obsessive-Compulsive Disorder Based on Machine Learning From a Primate Genetic Model
Abstract: Psychiatric disorders commonly comprise comorbid symptoms, such as autism spectrum disorder (ASD), obsessive-compulsive disorder (OCD), and attention deficit hyperactivity disorder (ADHD), raising controversies over accurate diagnosis and overlap of their neural underpinnings. The authors used noninvasive neuroimaging in humans and nonhuman primates to identify neural markers associated with DSM-5 diagnoses and quantitative measures of symptom severity. American Journal of Psychiatry (AJP), 2021 Paper / Link
Adversarial Domain Adaptation with Prototype-Based Normalized Output Conditioner
Abstract: In this work, we attempt to address unsupervised domain adaptation by devising simple and compact conditional domain adversarial training methods. We first revisit the simple concatenation conditioning strategy where features are concatenated with output predictions as the input of the discriminator. We find the concatenation strategy suffers from the weak conditioning strength. We further demonstrate that enlarging the norm of concatenated predictions can effectively energize the conditional domain alignment. Thus we improve concatenation conditioning by normalizing the output predictions to have the same norm of features, and term the derived method as Normalized OutpUt coNditioner~(NOUN). However, conditioning on raw output predictions for domain alignment, NOUN suffers from inaccurate predictions of the target domain. To this end, we propose to condition the cross-domain feature alignment in the prototype space rather than in the output space. Combining the novel prototype-based conditioning with NOUN, we term the enhanced method as PROtotype-based Normalized OutpUt coNditioner~(PRONOUN). Experiments on both object recognition and semantic segmentation show that NOUN can effectively align the multi-modal structures across domains and even outperform state-of-the-art domain adversarial training methods. Together with prototype-based conditioning, PRONOUN further improves the adaptation performance over NOUN on multiple object recognition benchmarks for UDA. IEEE Transactions on Image Processing (TIP), 2021 Paper / Link / Code
Deep Semantic Reconstruction Hashing for Similarity Retrieval
Abstract: Hashing has shown enormous potentials in preserving semantic similarity for large-scale data retrieval. Existing methods widely retain the similarity within two binary codes towards their discrete semantic affinity, i.e., 1 or -1. However, such a discrete reconstruction approach has obvious drawbacks. First, two unrelated dissimilar samples would have similar binary codes when both of them are the most dissimilar with an anchor sample. Second, the fine-grained semantic similarity cannot be shown in the generated binary codes among data with multiple semantic concepts. Furthermore, existing approaches generally adopt a point-wise error-minimizing strategy to enforce the real-valued codes close to its associated discrete codes, resulting in the well-learned paired semantic similarity being unintentionally damaged when performing quantization. To address these issues, we propose a novel deep hashing method with pairwise similarity-preserving quantization constraint, termed Deep Semantic Reconstruction Hashing (DSRH), which defines a high-level semantic affinity within each data pair to learn compact binary codes. Specifically, DSRH is expected to learn the specific binary codes whose similarity can reconstruct their high-level semantic similarity. Besides, we adopt a pairwise similarity-preserving quantization constraint instead of the traditional point-wise quantization technique, which is conducive to maintain the well-learned paired semantic similarity when performing quantization. Extensive experiments are conducted on four representative image retrieval benchmarks, and the proposed DSRH outperforms the state-of-the-art deep-learning methods with respect to different evaluation metrics. IEEE Transactions on Circuits and Systems for Video Technology (TCSVT), 2021 Paper / Link
Domain Adaptation with Auxiliary Target Domain-Oriented Classifier
Abstract: Domain adaptation (DA) aims to transfer knowledge from a label-rich but heterogeneous domain to a label-scare domain, which alleviates the labeling efforts and attracts considerable attention. Different from previous methods focusing on learning domain-invariant feature representations, some recent methods present generic semi-supervised learning (SSL) techniques and directly apply them to DA tasks, even achieving competitive performance. One of the most popular SSL techniques is pseudo-labeling that assigns pseudo labels for each unlabeled data via the classifier trained by labeled data. However, it ignores the distribution shift in DA problems and is inevitably biased to source data. To address this issue, we propose a new pseudo-labeling framework called Auxiliary Target Domain-Oriented Classifier (ATDOC). ATDOC alleviates the classifier bias by introducing an auxiliary classifier for target data only, to improve the quality of pseudo labels. Specifically, we employ the memory mechanism and develop two types of non-parametric classifiers, i.e. the nearest centroid classifier and neighborhood aggregation, without introducing any additional network parameters. Despite its simplicity in a pseudo classification objective, ATDOC with neighborhood aggregation significantly outperforms domain alignment techniques and prior SSL techniques on a large variety of DA benchmarks and even scare-labeled SSL tasks. IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2021 Paper / Link / Code / Slides
No Fear of Heterogeneity: Classifier Calibration for Federated Learning with Non-IID Data
Abstract: A central challenge in training classification models in the real-world federated system is learning with non-IID data. To cope with this, most of the existing works involve enforcing regularization in local optimization or improving the model aggregation scheme at the server. Other works also share public datasets or synthesized samples to supplement the training of under-represented classes or introduce a certain level of personalization. Though effective, they lack a deep understanding of how the data heterogeneity affects each layer of a deep classification model. In this paper, we bridge this gap by performing an experimental analysis of the representations learned by different layers. Our observations are surprising: (1) there exists a greater bias in the classifier than other layers, and (2) the classification performance can be significantly improved by post-calibrating the classifier after federated training. Motivated by the above findings, we propose a novel and simple algorithm called Classifier Calibration with Virtual Representations (CCVR), which adjusts the classifier using virtual representations sampled from an approximated gaussian mixture model. Experimental results demonstrate that CCVR achieves state-of-the-art performance on popular federated learning benchmarks including CIFAR-10, CIFAR-100, and CINIC-10. We hope that our simple yet effective method can shed some light on the future research of federated learning with non-IID data. Annual Conference on Neural Information Processing Systems (NeurIPS), 2021 Paper / Link
Unleashing the Power of Contrastive Self-Supervised Visual Models via Contrast-Regularized Fine-Tuning
Abstract: Contrastive self-supervised learning (CSL) has attracted increasing attention for model pre-training via unlabeled data. The resulted CSL models provide instance-discriminative visual features that are uniformly scattered in the feature space. During deployment, the common practice is to directly fine-tune CSL models with cross-entropy, which however may not be the best strategy in practice. Although cross-entropy tends to separate inter-class features, the resulting models still have limited capability for reducing intra-class feature scattering that exists in CSL models. In this paper, we investigate whether applying contrastive learning to fine-tuning would bring further benefits, and analytically find that optimizing the contrastive loss benefits both discriminative representation learning and model optimization during fine-tuning. Inspired by these findings, we propose Contrast-regularized tuning (Core-tuning), a new approach for fine-tuning CSL models. Instead of simply adding the contrastive loss to the objective of fine-tuning, Core-tuning further applies a novel hard pair mining strategy for more effective contrastive fine-tuning, as well as smoothing the decision boundary to better exploit the learned discriminative feature space. Extensive experiments on image classification and semantic segmentation verify the effectiveness of Core-tuning. Annual Conference on Neural Information Processing Systems (NeurIPS), 2021 Paper / Link / Code / Slides
Do We Really Need to Access the Source Data? Source Hypothesis Transfer for Unsupervised Domain Adaptation
Abstract: Unsupervised domain adaptation (UDA) aims to leverage the knowledge learned from a labeled source dataset to solve similar tasks in a new unlabeled domain. Prior UDA methods typically require to access the source data when learning to adapt the model, making them risky and inefficient for decentralized private data. This work tackles a practical setting where only a trained source model is available and investigates how we can effectively utilize such a model without source data to solve UDA problems. We propose a simple yet generic representation learning framework, named \emph{Source HypOthesis Transfer} (SHOT). SHOT freezes the classifier module (hypothesis) of the source model and learns the target-specific feature extraction module by exploiting both information maximization and self-supervised pseudo-labeling to implicitly align representations from the target domains to the source hypothesis. To verify its versatility, we evaluate SHOT in a variety of adaptation cases including closed-set, partial-set, and open-set domain adaptation. Experiments indicate that SHOT yields state-of-the-art results among multiple domain adaptation benchmarks. International Conference on Machine Learning (ICML), 2020 Paper / Link / Code / Slides
A Balanced and Uncertainty-aware Approach for Partial Domain Adaptation
Abstract: This work addresses the unsupervised domain adaptation problem, especially in the case of class labels in the target domain being only a subset of those in the source domain. Such a partial transfer setting is realistic but challenging and existing methods always suffer from two key problems, negative transfer and uncertainty propagation. In this paper, we build on domain adversarial learning and propose a novel domain adaptation method BA3US with two new techniques termed Balanced Adversarial Alignment (BAA) and Adaptive Uncertainty Suppression (AUS), respectively. On one hand, negative transfer results in misclassification of target samples to the classes only present in the source domain. To address this issue, BAA pursues the balance between label distributions across domains in a fairly simple manner. Specifically, it randomly leverages a few source samples to augment the smaller target domain during domain alignment so that classes in different domains are symmetric. On the other hand, a source sample would be denoted as uncertain if there is an incorrect class that has a relatively high prediction score, and such uncertainty easily propagates to unlabeled target data around it during alignment, which severely deteriorates adaptation performance. Thus we present AUS that emphasizes uncertain samples and exploits an adaptive weighted complement entropy objective to encourage incorrect classes to have uniform and low prediction scores. Experimental results on multiple benchmarks demonstrate our BA3US surpasses state-of-the-arts for partial domain adaptation tasks. European Conference on Computer Vision (ECCV), 2020 Paper / Link / Code / Slides
Aggregating Randomized Clustering-Promoting Invariant Projections for Domain Adaptation
Abstract: Unsupervised domain adaptation aims to leverage the labeled source data to learn with the unlabeled target data. Previous trandusctive methods tackle it by iteratively seeking a low-dimensional projection to extract the invariant features and obtaining the pseudo target labels via building a classifier on source data. However, they merely concentrate on minimizing the cross-domain distribution divergence, while ignoring the intra-domain structure especially for the target domain. Even after projection, possible risk factors like imbalanced data distribution may still hinder the performance of target label inference. In this paper, we propose a simple yet effective domain-invariant projection ensemble approach to tackle these two issues together. Specifically, we seek the optimal projection via a novel relaxed domain-irrelevant clustering-promoting term that jointly bridges the cross-domain semantic gap and increases the intra-class compactness in both domains. To further enhance the target label inference, we first develop a `sampling-and-fusion' framework, under which multiple projections are independently learned based on various randomized coupled domain subsets. Subsequently, aggregating models such as majority voting are utilized to leverage multiple projections and classify unlabeled target data. Extensive experimental results on six visual benchmarks including object, face, and digit images, demonstrate that the proposed methods gain remarkable margins over state-of-the-art unsupervised domain adaptation methods. IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 2019 Paper / Appendix / Link / Code / Office-Home-ResNet-features (password: rb13)]
Local Semantic-aware Deep Hashing with Hamming-isometric Quantization
Abstract: Hashing is a promising approach for compact storage and efficient retrieval of big data. Compared to the conventional hashing methods using handcrafted features, emerging deep hashing approaches employ deep neural networks to learn both feature representations and hash functions, which have been proven to be more powerful and robust in real-world applications. Currently, most of the existing deep hashing methods construct pairwise or triplet-wise constraints to obtain similar binary codes between a pair of similar data points or relatively similar binary codes within a triplet. However, we argue that some critical local structures have not been fully exploited. So, this paper proposes a novel deep hashing method named local semantic-aware deep hashing with Hamming-isometric quantization (LSDH), aiming to make full use of local similarity in hash function learning. Specifically, the potential semantic relation is exploited to robustly preserve local similarity of data in the Hamming space. In addition to reducing the error introduced by binary quantizing, a Hamming-isometric objective is designed to maximize the consistency of similarity between the pairwise binary-like features and corresponding binary codes pair, which is shown to be able to improve the quality of binary codes. Extensive experimental results on several benchmark datasets, including three single-label datasets and one multi-label dataset, demonstrate that the proposed LSDH achieves better performance than the latest state-of-the-art hashing methods. IEEE Transactions on Image Processing (TIP), 2019 Paper / Link
Exploring Uncertainty in Pseudo-label Guided Unsupervised Domain Adaptation
Abstract: Due to the unavailability of labeled target data, most existing unsupervised domain adaptation (UDA) methods alternately classify the unlabeled target samples and discover a low-dimensional subspace by mitigating the cross-domain distribution discrepancy. During the pseudo-label guided subspace discovery step, however, the posterior probabilities (uncertainties) from the previous target label estimation step are totally ignored, which may promote the error accumulation and degrade the adaptation performance. To address this issue, we propose to progressively increase the number of target training samples and incorporate the uncertainties to accurately characterize both cross-domain distribution discrepancy and other intra-domain relations. Specifically, we exploit maximum mean discrepancy (MMD) and within-class variance minimization for these relations, yet, these terms merely focus on the global class structure while ignoring the local structure. Then, a triplet-wise instance-to-center margin is further maximized to push apart target instances and source class centers of different classes and bring closer them of the same class. Generally, an EM-style algorithm is developed by alternating between inferring uncertainties, progressively selecting certain training target samples, and seeking the optimal feature transformation to bridge two domains. Extensive experiments on three popular visual domain adaptation datasets demonstrate that our method significantly outperforms recent state-of-the-art approaches. Pattern Recognition (PR), 2019 Paper / Link / Code
Distant Supervised Centroid Shift: A Simple and Efficient Approach to Visual Domain Adaptation
Abstract: Conventional domain adaptation methods usually resort to deep neural networks or subspace learning to find invariant representations across domains. However, most deep learning methods highly rely on large-size source domains and are computationally expensive to train, while subspace learning methods always have a quadratic time complexity that suffers from the large domain size. This paper provides a simple and efficient solution, which could be regarded as a well-performing baseline for domain adaptation tasks. Our method is built upon the nearest centroid classifier, seeking a subspace where the centroids in the target domain are moderately shifted from those in the source domain. Specifically, we design a unified objective without accessing the source domain data and adopt an alternating minimization scheme to iteratively discover the pseudo target labels, invariant subspace, and target centroids. Besides its privacy-preserving property (distant supervision), the algorithm is provably convergent and has a promising linear time complexity. In addition, the proposed method can be readily extended to multi-source setting and domain generalization, and it remarkably enhances popular deep adaptation methods by borrowing the learned transferable features. Extensive experiments on several benchmarks including object, digit, and face recognition datasets validate that our methods yield state-of-the-art results in various domain adaptation tasks. IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2019 Paper / Link / Code
Deep Spatial Feature Reconstruction for Partial Person Re-Identification: Alignment-Free Approach
Abstract: Partial person re-identification (re-id) is a challenging problem, where only a partial observation of a person image is available for matching. However, few studies have offered a solution of how to identify an arbitrary patch of a person image. In this paper, we propose a fast and accurate matching method to address this problem. The proposed method leverages Fully Convolutional Network (FCN) to generate correspondingly-size spatial feature maps such that pixel-level features are consistent. To match a pair of person images of different sizes, a novel method called Deep Spatial feature Reconstruction (DSR) is further developed to avoid explicit alignment. Specifically, we exploit the reconstructing error from dictionary learning to calculate the similarity between different spatial feature maps. In that way, we expect that the proposed FCN can decrease the similarity of coupled images from different persons and vice versa. Experimental results on two partial person datasets demonstrate the efficiency and effectiveness of the proposed method in comparison with several state-of-the-art partial person re-id approaches. IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2018 Paper / Link / Code
X-GACMN: An X-Shaped Generative Adversarial Cross-Modal Network with Hypersphere Embedding
Abstract: How to bridge heterogeneous gap between different modalities is one of the main challenges in cross-modal retrieval task. Most existing methods try to tackle this problem by projecting data from different modalities into a common space. In this paper, we introduce a novel X-Shaped Generative Adversarial Cross-Modal Network (X-GACMN) to learn a better common space between different modalities. Specifically, the proposed architecture combines the process of synthetic data generation and distribution adapting into a unified framework to make sure the heterogeneous modality distributions similar to each other in the learned common subspace. To promote the discriminative ability, a new loss function that combines intra-modality angular softmax loss and cross-modality pair-wise consistent loss is further imposed on the common space, hence the learned features can well preserve both inter-modality structure and intra-modality structure on a hypersphere manifold. Extensive experiments on three benchmark datasets show the effectiveness of the proposed approach. Asian Conference on Computer Vision (ACCV), 2018 Paper / Link
Learning Discriminative Geodesic Flow Kernel for Unsupervised Domain Adaptation
Abstract: Extracting the domain-invariant features provides an important intuition for unsupervised domain adaptation. Due to the unavailable target labels, it is difficult to guarantee that the learned domain-invariant features are good for target instances classification. In this paper, we extend the classic geodesic flow kernel method by leveraging the pseudo labels during the training process to learn a discriminative geodesic flow kernel for unsupervised domain adaptation. Specifically, the proposed method alternately discovers the pseudo target labels and builds the geodesic flow from a discriminative source subspace to another ‘discriminative’ target subspace. More specially, the pseudo target labels are inferred via the learned kernel based on an easy yet effective label propagation strategy. Hence, the proposed method not only holds the property of domain-invariance, but also maximizes the consistency between pseudo label structure and data structure. Experimental results illustrate that the proposed method outperforms the state-of-the-art unsupervised domain adaptation methods for object recognition and sentiment analysis. IEEE International Conference on Multimedia and Expo (ICME), Oral, 2018 Paper / Link / Slides
Nonlinear Discrete Cross-Modal Hashing for Visual-Textual Data
Abstract: Hashing techniques have been widely adopted for cross-modal retrieval due to their low storage cost and fast query speed. Recently, some unimodal hashing methods have tried to directly optimize the objective function with discrete binary constraints. Inspired by these methods, the authors propose a novel supervised cross-modal hashing method called Discrete Cross-Modal Hashing (DCMH) to learn the binary codes without relaxing them. DCMH is formulated through semantic similarity reconstruction, and it learns binary codes for use as ideal features for classification. Furthermore, DCMH alternately updates binary codes for each modality, and its discrete hashing codes are learned efficiently, bit by bit, which is quite promising for large-scale datasets. To evaluate the effectiveness of the proposed discrete optimization, the authors optimize their objective function in a relax-and-threshold manner. Extensive empirical results on both image-text and image-tag datasets demonstrate that DCMH is a significant improvement over previous approaches in terms of training time and retrieval performance. IEEE MultiMedia (IEEE MM), 2017 Paper / Link / Code
Self-Paced Learning: an Implicit Regularization Perspective
Abstract: Self-paced learning (SPL) mimics the cognitive mechanism of humans and animals that gradually learns from easy to hard samples. One key issue in SPL is to obtain better weighting strategy that is determined by the minimizer function. Existing methods usually pursue this by artificially designing the explicit form of SPL regularizer. In this paper, we study a group of new regularizer (named self-paced implicit regularizer) that is deduced from robust loss function. Based on the convex conjugacy theory, the minimizer function for self-paced implicit regularizer can be directly learned from the latent loss function, while the analytic form of the regularizer can be even unknown. A general framework (named SPL-IR) for SPL is developed accordingly. We demonstrate that the learning procedure of SPL-IR is associated with latent robust loss functions, thus can provide some theoretical insights for its working mechanism. We further analyze the relation between SPL-IR and half-quadratic optimization and provide a group of self-paced implicit regularizer. Finally, we implement SPL-IR to both supervised and unsupervised tasks, and experimental results corroborate our ideas and demonstrate the correctness and effectiveness of implicit regularizers. AAAI Conference on Artificial Intelligence (AAAI), Oral, 2017 Paper / Link
Self-Paced Cross-Modal Subspace Matching
Abstract: Cross-modal matching methods match data from different modalities according to their similarities. Most existing methods utilize label information to reduce the semantic gap between different modalities. However, it is usually time-consuming to manually label large-scale data. This paper proposes a Self-Paced Cross-Modal Subspace Matching (SCSM) method for unsupervised multimodal data. We assume that multimodal data are pair-wised and from several semantic groups, which form hard pair-wised constraints and soft semantic group constraints respectively. Then, we formulate the unsupervised cross-modal matching problem as a non-convex joint feature learning and data grouping problem. Self-paced learning, which learns samples from 'easy' to 'complex', is further introduced to refine the grouping result. Moreover, a multimodal graph is constructed to preserve the relationship of both inter- and intra-modality similarity. An alternating minimization method is employed to minimize the non-convex optimization problem, followed by the discussion on its convergence analysis and computational complexity. Experimental results on four multimodal databases show that SCSM outperforms state-of-the-art cross-modal subspace learning methods. International ACM SIGIR conference on Research and Development in Information Retrieval (SIGIR), Oral, 2016 Paper Link / Slides / Code / Dataset
Group-Invariant Cross-Modal Subspace Learning
Abstract: Cross-modal learning tries to find various types of heterogeneous data (e.g., image) from a given query (e.g., text). Most cross-modal algorithms heavily rely on semantic labels and benefit from a semantic-preserving aggregation of pairs of heterogeneous data. However, the semantic labels are not readily obtained in many real-world applications. This paper studies the aggregation of these pairs unsupervisedly. Apart from lower pairwise correspondences that force the data from one pair to be close to each other, we propose a novel concept, referred as groupwise correspondences, supposing that each paired heterogeneous data are from an identical latent group. We incorporate this groupwise correspondences into canonical correlation analysis (CCA) model, and seek a latent common subspace where data are naturally clustered into several latent groups. To simplify this nonconvex and nonsmooth problem, we introduce a non-negative orthogonal variable to represent the soft group membership, then two coupled computationally efficient subproblems (a generalized ratio-trace problem and a non-negative problem) are alternatively minimized to guarantee the proposed algorithm converges locally. Experimental results on two benchmark datasets demonstrate that the proposed unsupervised algorithm even achieves comparable performance to some state-of-the-art supervised cross-modal algorithms. International Joint Conference on Artificial Intelligence (IJCAI), Oral, 2016 Paper / Link / Code / Slides
Frustratingly Easy Cross-Modal Hashing
Abstract: Cross-modal hashing has attracted considerable attention due to its low storage cost and fast retrieval speed. Recently, more and more sophisticated researches related to this topic are proposed. However, they seem to be inefficient computationally for several reasons. On one hand, learning coupled hash projections makes the iterative optimization problem challenging. On the other hand, individual collective binary codes for each content are also learned with a high computation complexity. In this paper we describe a simple yet effective cross-modal hashing approach that can be implemented in just three lines of code. This approach first obtains the binary codes for one modality via unimodal hashing methods (e.g., iterative quantization (ITQ)), then applies simple linear regression to project the other modalities into the obtained binary subspace. Obviously, it is non-iterative and parameter-free, which makes it more attractive for many real-world applications. We further compare our approach with other state-of-the-art methods on four benchmark datasets (i.e., the Wiki, VOC, LabelMe and NUS-WIDE datasets). Despite its extraordinary simplicity, our approach performs remarkably and generally well for these datasets under different experimental settings (i.e., large-scale, high-dimensional and multi-label datasets). ACM International Conference on Multimedia (ACM MM), 2016 Paper / Link / Code / Dataset
Discrete Cross-Modal Hashing for Efficient Multimedia Retrieval
Abstract: Hashing techniques have been widely adopted for cross-modal retrieval due to its low storage cost and fast query speed. Most existing cross-modal hashing methods aim to map heterogeneous data into the common low-dimensional hamming space and then threshold to obtain binary codes by relaxing the discrete constraint. However, this independent relaxation step also brings quantization errors, resulting in poor retrieval performances. Other cross-modal hashing methods try to directly optimize the challenging objective function with discrete binary constraints. Inspired by [1], we propose a novel supervised cross-modal hashing method called Discrete Cross-Modal Hashing (DCMH) to learn the discrete binary codes without relaxing them. DCMH is formulated through reconstructing the semantic similarity matrix and learning binary codes as ideal features for classification. Furthermore, DCMH alternately updates binary codes of each modality, and iteratively learns the discrete hashing codes bit by bit efficiently, which is quite promising for large-scale datasets. Extensive empirical results on three real-world datasets show that DCMH outperforms the baseline approaches significantly. IEEE International Symposium on Multimedia (ISM), Best Paper Candidate, 2016 Paper / Link
Code Consistent Hashing Based on Information-Theoretic Criterion
Abstract: Learning based hashing techniques have attracted broad research interests in the Big Media research area. They aim to learn compact binary codes which can preserve semantic similarity in the Hamming embedding. However, the discrete constraints imposed on binary codes typically make hashing optimizations very challenging. In this paper, we present a code consistent hashing (CCH) algorithm to learn discrete binary hash codes. To form a simple yet efficient hashing objective function, we introduce a new code consistency constraint to leverage discriminative information and propose to utilize the Hadamard code which favors an information-theoretic criterion as the class prototype. By keeping the discrete constraint and introducing an orthogonal constraint, our objective function can be minimized efficiently. Experimental results on three benchmark datasets demonstrate that the proposed CCH outperforms state-of-the-art hashing methods in both image retrieval and classification tasks, especially with short binary codes. IEEE Transactions on Big Data (TBD), 2015 Paper / Link
Two-Step Greedy Subspace Clustering
Abstract: Greedy subspace clustering methods provide an efficient way to cluster large-scale multimedia datasets. However, these methods do not guarantee a global optimum and their clustering performance mainly depends on their initializations. To alleviate this initialization problem, this paper proposes a two-step greedy strategy by exploring proper neighbors that span an initial subspace. Firstly, for each data point, we seek a sparse representation with respect to its nearest neighbors. The data points corresponding to nonzero entries in the learning representation form an initial subspace, which potentially rejects bad or redundant data points. Secondly, the subspace is updated by adding an orthogonal basis involved with the newly added data points. Experimental results on real-world applications demonstrate that our method can significantly improve the clustering accuracy of greedy subspace clustering methods without scarifying much computational time. Advances in Multimedia Information Processing (PCM), Oral, 2015 Paper / Link
Principal Affinity Based Cross-Modal Retrieval
Abstract: Multimedia content is increasingly available in multiple modalities. Each modality provides a different representation of the same entity. This paper studies the problem of joint representation of the text and image components of multimedia documents. However, most existing algorithms focus more on inter-modal connection rather than intramodal feature extraction. In this paper, a simple yet effective principal affinity representation (PAR) approach is proposed to exploit the affinity representations of different modalities with local cluster samples. Afterwards, multi-class logistic regression model is adopted to learn the projections from principal affinity representation to semantic labels vectors. Inner product distance is further used to improve cross-modal retrieval performance. Extensive experiments on three benchmark datasets illustrate that our proposed method obtains significant improvements over the state-of-the-art subspace learning based cross-modal methods. IAPR Asian Conference on Pattern Recognition (ACPR), 2015 Paper / Link / Code |
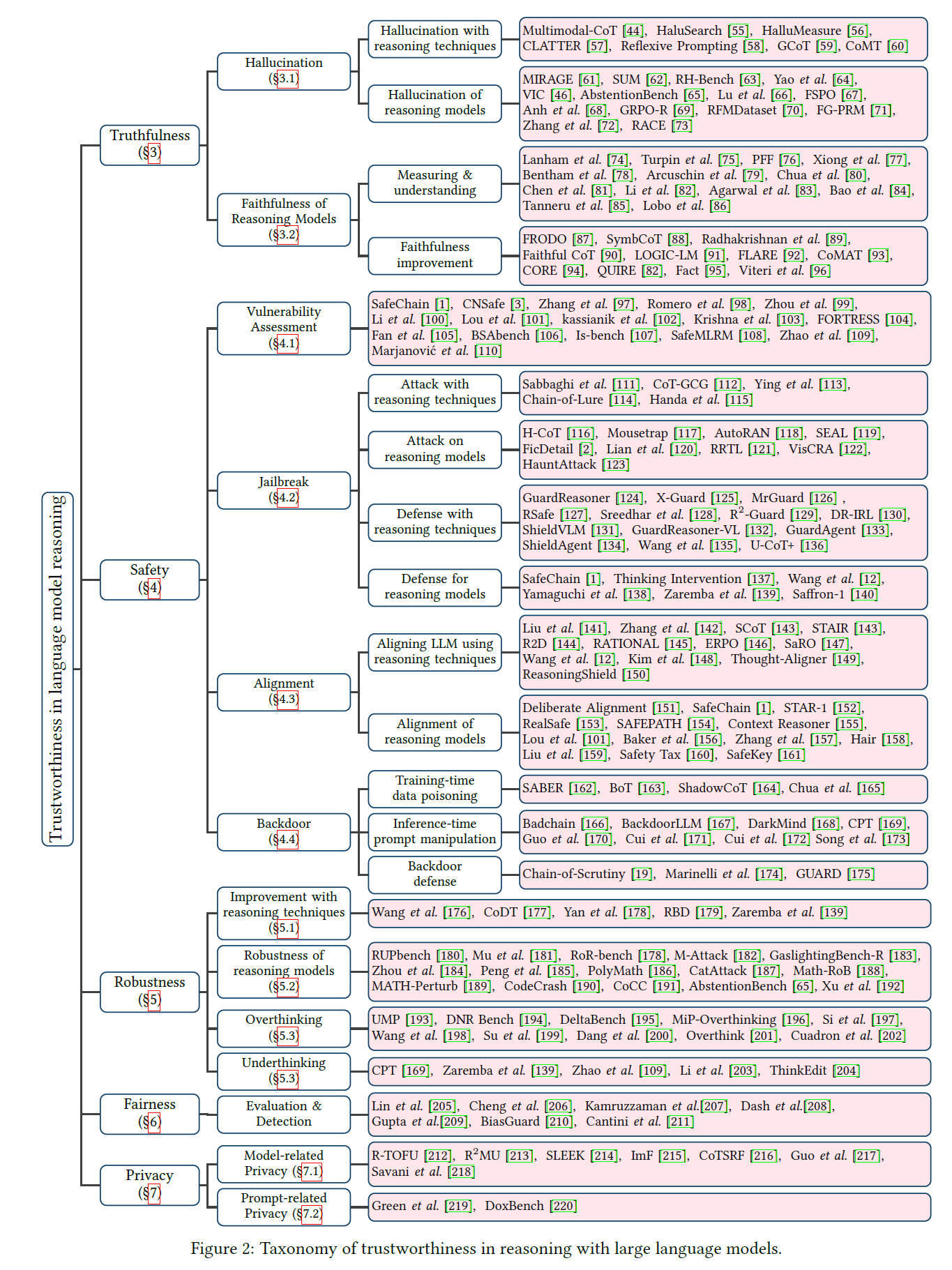{kind=link}